VALL-E - AI Tool
Simulate anyone’s voice with 3 seconds of audio
About VALL-E
The new Text-to-speech model from Microsoft can preserve speaker's emotional tone and acoustic environment.
VALL-E could be used for high-quality text-to-speech applications, speech editing where a recording of a person could be edited and changed from a text transcript (making them say something they originally didn't), and audio content creation when combined with other generative AI models like GPT-3.
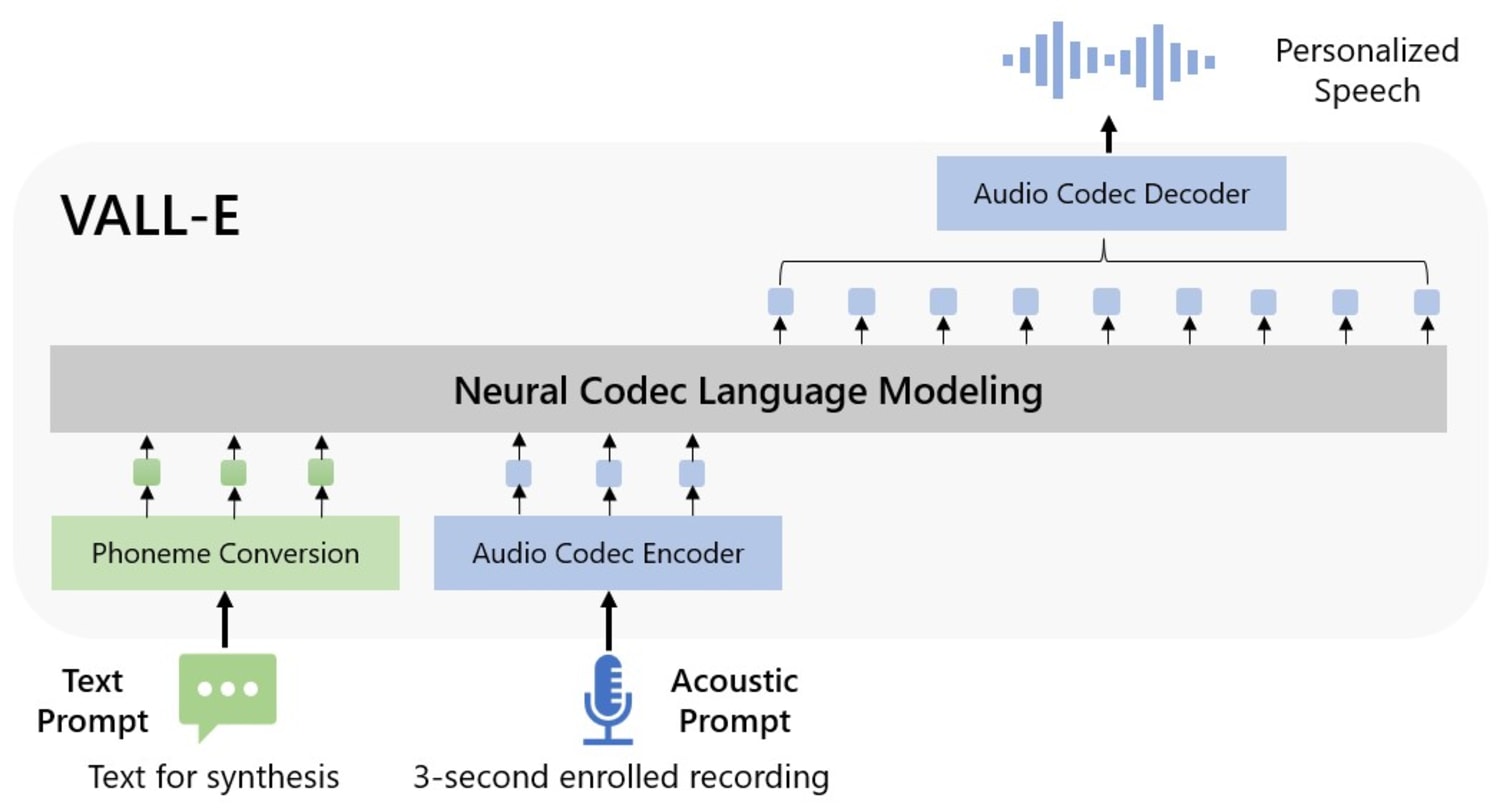
Microsoft calls VALL-E a "neural codec language model," and it builds off of a technology called EnCodec, which Meta announced in October 2022. Unlike other text-to-speech methods that typically synthesize speech by manipulating waveforms, VALL-E generates discrete audio codec codes from text and acoustic prompts. It basically analyzes how a person sounds, breaks that information into discrete components (called "tokens") thanks to EnCodec, and uses training data to match what it "knows" about how that voice would sound if it spoke other phrases outside of the three-second sample.
For the paper's conclusion, they write:
"Since VALL-E could synthesize speech that maintains speaker identity, it may carry potential risks in misuse of the model, such as spoofing voice identification or impersonating a specific speaker. To mitigate such risks, it is possible to build a detection model to discriminate whether an audio clip was synthesized by VALL-E. We will also put Microsoft AI Principles into practice when further developing the models."